Publication,
Research,
Docs and Info,
KAMEDA
When the dynamic objects are imaged by a camera i, they exist within
frustums that circumscribe their projected regions on the image
and whose apexes are focus point of the camera. We call all the
projected regions in the same image together a dynamic region
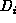 and let us denote a subspace consisting of these viewing
frustums by
and let us denote a subspace consisting of these viewing
frustums by 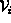 .
.
As the dynamic objects can exist only outside 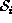 , we only
care a subspace named existence shadow subspace (ESS)
, we only
care a subspace named existence shadow subspace (ESS)
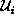 defined by Equation (1).
defined by Equation (1).
The dynamic objects exist somewhere inside 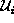 .
.
In the case where the dynamic objects are imaged by n cameras, they
exist within the product of all of these frustums. We denote this
subspace as 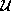 where
where
Suppose there are n cameras in the real space and the cameras capture
images simultaneously. We call this set of images a frame. 3D
reconstruction process named 3D composer can generate 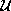 at each frame in the condition that it is given
at each frame in the condition that it is given 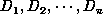 because
because 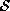 and the focus positions of the
cameras are given in advance. Since
and the focus positions of the
cameras are given in advance. Since 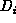 is described by a binary
image, the amount of transferred data is quite small.
is described by a binary
image, the amount of transferred data is quite small.
This 3D reconstruction calculation in Equation (2) is easily expanded to parallel distributed computing because several 3D composers can reconstruct different subspaces simultaneously. Thus we achieve spatio-division of the 3D reconstruction process based on the locality of 3D reconstruction calculation.
In the actual implementation, 3D composer generates 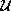 by voxel
representation.
by voxel
representation.

